
Solidity developers have long dreaded the infamous “Stack too deep” error. To work around it, they often split functions, pack variables into structs, or manually offload values to memory — just to get the code to compile. It’s been a persistent pain point, with prominent Ethereum engineers openly questioning why it remains unresolved. One partial solution is the --via-ir flag, which allows the compiler to automatically move excess variables to memory instead of relying solely on DUP and SWAP for stack manipulation. It mostly works — but with a major caveat: it can subtly change the semantics of a contract. The result? Most projects remain on the legacy compiler path, doing “stack too deep” workarounds, leaving the underlying problem unsolved.
solx removes the error entirely while keeping your contract’s behavior bit-for-bit identical.
solx memory layout and current constraints
Solx extends solidity’s memory layout — similarly to solc --via-ir — by inserting a dedicated region for spills. This guarantees that spills never interfere with user memory:
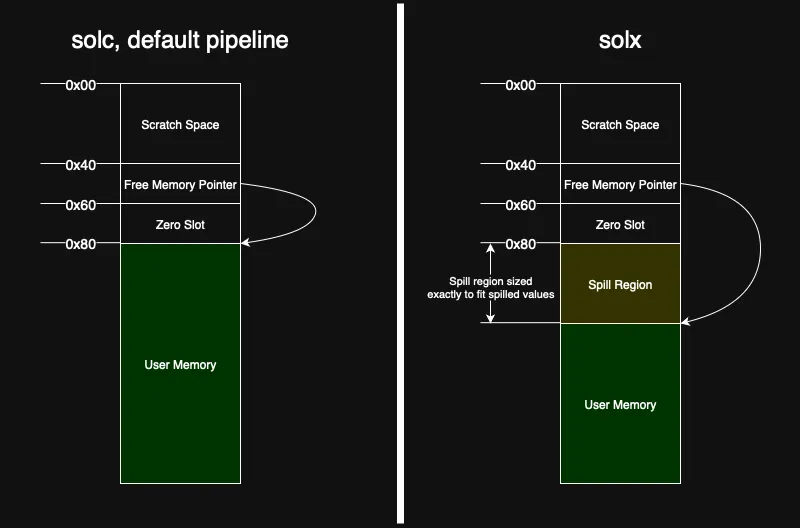
The spill region is laid out at compile time: the frontend reserves it starting at the first safe offset (0x80), the backend calculates the exact size of this region, and the free memory pointer (0x40) is updated to point immediately after it. Because the region cannot grow at runtime and all heap allocations begin beyond its end, neither user code nor memory-safe inline assembly can touch a spill slot, and a spill write can never run past its bounds. Memory corruption is therefore impossible by design.
This deterministic layout comes with an intentional tradeoff: self-recursive and indirectly recursive functions are not supported. Supporting recursion would require allocating a fresh set of spill slots for each call, but solx deliberately avoids dynamic memory allocation for spills. As a result, recursive functions are explicitly rejected at compile time if they have “stack too deep” issues. Developers writing inline assembly should be careful. When spilling is required and a contract contains an assembly block without the memory-safe annotation, solx will produce an error like the following:
Error (5726): This contract cannot be compiled due to a combination of a memory-unsafe assembly block and a stack-too-deep error. The compiler can automatically fix the stack-too-deep error, but only in the absence of memory-unsafe assembly.
To successfully compile this contract, please check if this assembly block is memory-safe according to the requirements at
https://docs.soliditylang.org/en/latest/assembly.html#memory-safety
and then mark it with a memory-safe tag.
Alternatively, if you feel confident, you may suppress this error project-wide by setting the EVM_DISABLE_MEMORY_SAFE_ASM_CHECK environment variable:
EVM_DISABLE_MEMORY_SAFE_ASM_CHECK=1 <your build command>
Please be aware of the memory corruption risks described at the link above!
--> forge/test/strategy/CommonBaseTest.t.sol:25:9:
|
25 | assembly {
| ^ (Relevant source part starts here and spans across multiple lines).
If an assembly block is memory-safe, it must be explicitly annotated with "memory-safe" to inform the compiler that it can safely reserve space for the spill region and emit spills.
On the other hand, if an assembly block is not memory-safe but is incorrectly annotated as such, it can lead to incorrect and undefined behavior — since memory used for spills may be overwritten unexpectedly.
There are also a few important current limitations to keep in mind. First, the EVM imposes a hard limit of 1024 elements on the operand stack, but solx does not currently track this global stack depth during code generation. While this rarely poses a problem in typical contracts, it may become relevant in cases involving very deep nesting or aggressive inlining. If the limit is exceeded at runtime, execution will fail without prior compiler warnings.
Another limitation arises when functions have a large number of arguments or return values — typically more than 16. In such cases, “stack too deep” issues may occur during stackification. While solx can often recover by spilling intermediate values to memory, this is not guaranteed in all scenarios, particularly when values remain live across complex control flow.
solx memory spills vs solc --via-ir
Both solc --via-ir and solx aim to solve the same problem: fixing “stack too deep” issues in EVM by introducing memory spills. However, they approach this problem with very different strategies.
solc’s StackLimitEvader makes assumptions about potential stack pressure and rewrites code to preemptively store intermediate results in memory. These spills are generally safe but tend to be precautionary, and once a value is stored in memory, the slot is not reused, even if it’s no longer needed. In some cases, contracts may still fail with “stack too deep” errors, as seen in several reported issues on GitHub.
In contrast, solx inserts spills during stackification, but only when needed. Memory slots are reused based on LLVM’s internal analysis, which considers liveness information. This reuse is not the result of custom logic in solx, but a natural benefit of LLVM’s infrastructure. solx pays more at compile time to produce more efficient and compact runtime code — an intentional tradeoff. Rather than assuming stack pressure might occur, it emits spills only when they are truly necessary.
Stack too deep resolvability table
This table illustrates the state of “stack too deep” solutions across different pipelines and codegens. We can see that thanks to additional IRs added on top of EVM assembly in the eponymous codegen, it becomes the most robust set of compiler settings without dangerous semantic changes that --via-ir could bring.
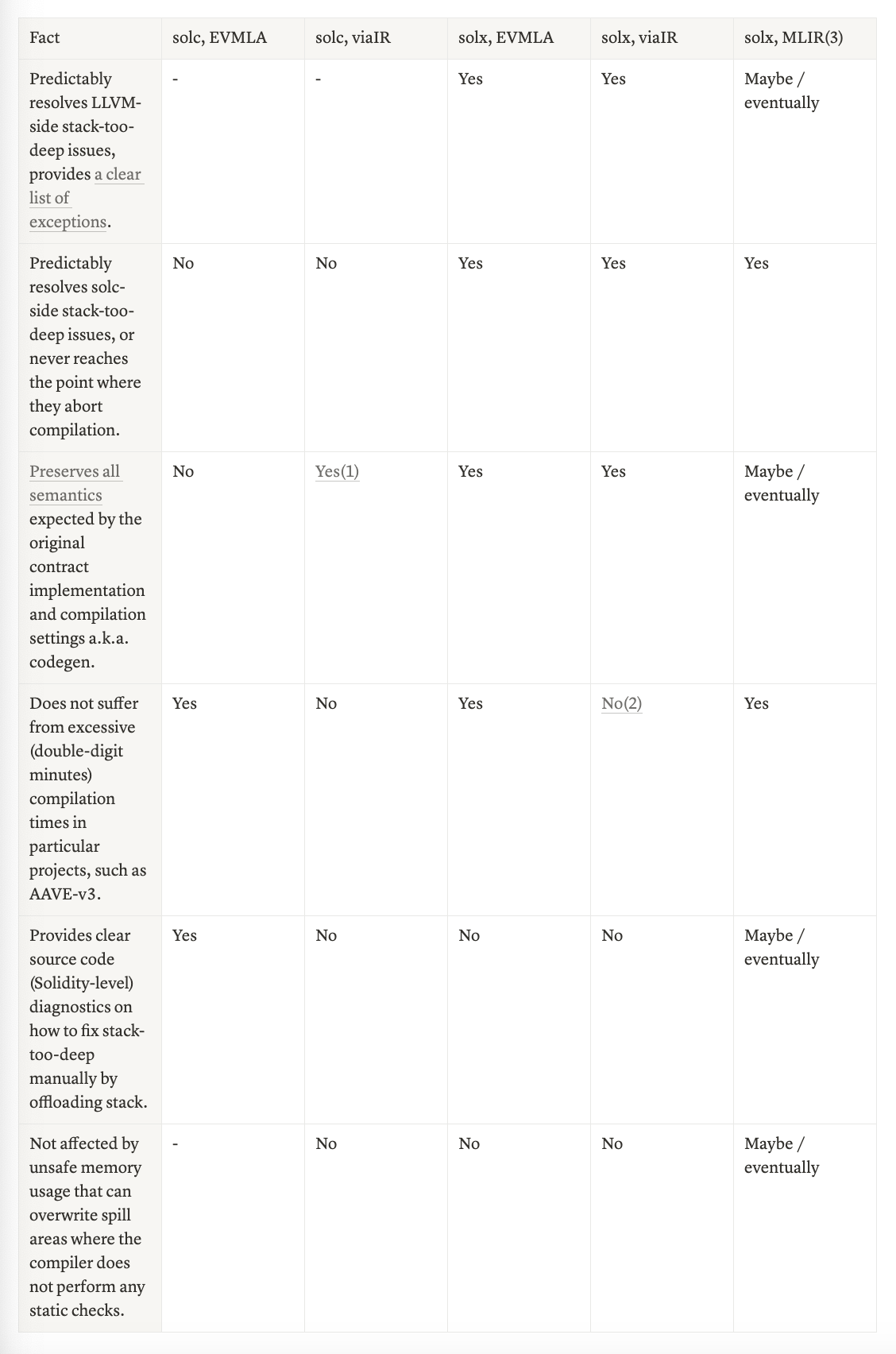
-
Only if the project was developed with viaIR, or migrated and has been tested later (total <20% of live projects).
-
Turning off the Yul optimizer from solx can alleviate the issue while keeping its library inlining intact.
- It is coming in next releases of solx.
-
MLIR is a new codegen that will supersede EVM assembly and Yul in solx. It is still work-in-progress, but we’re going to share some interesting news soon.
From spills that just works to a production grade
When we began addressing “stack too deep” issues in solx this May, our expectations were modest. The immediate goal was pragmatic: unblock the largest real-world contracts that failed to compile in our early pre-alpha releases. The plan was simple — spill whatever caused “stack too deep” and prioritize correctness over performance. If a contract compiled, that was already a win, even if it meant some gas inefficiency. With just a few months of work, we didn’t anticipate significant improvements over solc on those same contracts. And even if we wanted to improve the implementation, LLVM seemed like an unlikely candidate for help. The EVM is a stack machine without registers, while LLVM was built for register-based architectures. Its register allocation infrastructure appeared irrelevant to a stack-based target.
Both expectations proved wrong. First, in the majority of real-world contracts we tested (around 2000 from production-grade projects), solx outperforms solc — even when spilling is required. Second, LLVM provides a solid foundation for building production-grade code generation — even for a stack-based architecture — allowing us to move quickly and iterate with minimal custom effort. What began as a simple implementation quickly evolved into a robust and efficient solution.
Choosing which register to spill
Spills are determined during stackification — the phase where code is lowered from an intermediate representation into the EVM’s bytecode. Registers that cannot be reached via DUP or SWAP are spilled to memory and later reloaded when needed. This process proceeds iteratively until all “stack too deep” issues are resolved.
In our initial implementation of register spilling, we selected a register that was unreachable via the DUP or SWAP instructions. While this approach ensured correctness, it resulted in a high number of spills. To improve on this, we used LLVM’s register weight heuristic, which estimates the cost of spilling each virtual register based on its usage frequency and live range:
let x := add(a, b)
let y := sub(c, d)
pop(init(y)) // first use of y
// Inside a loop
...
let z := mul(x, e) // first use of x
...
pop(final(x)) // second use of x
pop(done(y)) // second use of y
// Weights:
x: high - used in the loop
y: low - used outside the loop
=> Heuristic prefers spilling y
At the point where a register becomes unreachable, the set of live registers from that register up to the top of the stack is examined, and the one with the lowest weight — the least expensive to spill — is selected. This change, combined with refining the heuristic to account for the number of uses of each register within the function, reduced the number of registers that needed to be spilled by an average of 65%. To enable this, we simply needed to hook into LLVM’s existing infrastructure, with a small customization to adjust for usage counts:
/// EVM-specific implementation of weight normalization.
class EVMVirtRegAuxInfo final : public VirtRegAuxInfo {
float normalize(float UseDefFreq, unsigned Size, unsigned NumInstr) override {
// All intervals have a spill weight that is mostly proportional to the
// number of uses, with uses in loops having a bigger weight.
return NumInstr * VirtRegAuxInfo::normalize(UseDefFreq, Size, 1);
}
public:
EVMVirtRegAuxInfo(MachineFunction &MF, LiveIntervals &LIS,
const VirtRegMap &VRM, const MachineLoopInfo &Loops,
const MachineBlockFrequencyInfo &MBFI)
: VirtRegAuxInfo(MF, LIS, VRM, Loops, MBFI) {}
};
EVMVirtRegAuxInfo EVRAI(MF, LIS, VRM, *MLI, MBFI);
// Use LLVM's heuristic to assign weights to registers
EVRAI.calculateSpillWeightsAndHints();
Reducing spill memory
As the implementation matured, we introduced StackSlotColoring, a standard LLVM pass that reuses stack slots for variables whose lifetimes don’t overlap — meaning if two values are never alive at the same time, they can safely be assigned to the same memory location. Previously, each spill was assigned a dedicated slot, resulting in excessive memory usage. Enabling coloring, led to an average 25% reduction in allocated spill slots across multiple cases. Notably, this optimization was achieved with minimal effort by updating the analysis used by the pass and running that pass — demonstrating the advantages of leveraging LLVM’s infrastructure:
// Updating the analysis
StackSlot = VRM.assignVirt2StackSlot(Reg);
auto &StackInt =
LSS.getOrCreateInterval(StackSlot, MF.getRegInfo().getRegClass(Reg));
StackInt.getNextValue(SlotIndex(), LSS.getVNInfoAllocator());
StackInt.MergeSegmentsInAsValue(LIS.getInterval(Reg),
StackInt.getValNumInfo(0));
// Running the pass
addPass(&StackSlotColoringID);
Small implementation, big infrastructure
To give you a sense of the implementation effort and code impact, the following output highlights the changes introduced by this feature in the solx EVM backend, how much code was reused and the implementation from solc. The solx implementation took approximately two months, while the original solc implementation required at least three and a half months, as indicated by this PR — possibly even longer.
Code changes introduced by the feature:
---------------------------------------------------------------------------------------
Language new files added blank comment code
---------------------------------------------------------------------------------------
C++ 2 100 116 495
C/C++ Header 0 7 10 55
TableGen 0 1 0 3
CMake 0 0 0 2
---------------------------------------------------------------------------------------
SUM: 2 108 126 555
---------------------------------------------------------------------------------------
Reused LLVM code:
llvm/include/llvm/CodeGen/CalcSpillWeights.h
llvm/include/llvm/CodeGen/LiveIntervals.h
llvm/include/llvm/CodeGen/LiveStacks.h
llvm/include/llvm/CodeGen/MachineBlockFrequencyInfo.h
llvm/include/llvm/CodeGen/VirtRegMap.h
llvm/lib/CodeGen/CalcSpillWeights.cpp
llvm/lib/CodeGen/LiveIntervals.cpp
llvm/lib/CodeGen/LiveStacks.cpp
llvm/lib/CodeGen/MachineBlockFrequencyInfo.cpp
llvm/lib/CodeGen/StackSlotColoring.cpp
llvm/lib/CodeGen/VirtRegMap.cpp
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 6 476 644 2650
C/C++ Header 5 212 346 567
-------------------------------------------------------------------------------
SUM: 11 688 990 3217
-------------------------------------------------------------------------------
solc:
libyul/optimiser/StackLimitEvader.cpp
libyul/optimiser/StackLimitEvader.h
libyul/optimiser/StackToMemoryMover.cpp
libyul/optimiser/StackToMemoryMover.h
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C++ 2 59 64 456
C/C++ Header 2 24 179 85
-------------------------------------------------------------------------------
SUM: 4 83 243 541
-------------------------------------------------------------------------------
Avoiding solc’s stack depth limits in legacy mode
One might assume we're simply relying on solc in legacy mode to compile contracts without running into “stack too deep” issues. But that’s not the full story. We’ve also modified solc itself to successfully produce EVM assembly by emitting extended stack manipulation instructions — specifically SWAPX and DUPX. These allow us to defer stack layout resolution to the LLVM backend, where the stackification and spill handling are performed in a controlled and optimized way.
If you have any thoughts, questions, or feedback — we’d love to hear it. You can reach us directly on Telegram. At the end of the day, we want solx to be useful to you. And if you haven’t tried it yet, head over to solx.zksync.io and get started in just a few clicks.